scrapy.org
seguridad hacker
Como hackear wordpress
Estudiando mucho, campeón.
ssh-keygen
Como crear los “keys” para “ssh login” automático
Para los que bregamos con paginas web y desarrollo de aplicaciones basadas en tecnología web, el hacer ssh (remote login) a un servidor en el web es cosa de todos los dias.Vía ssh tenemos control absoluto de esos servidores remotos y nos permite usar herramientas como SVN o Git para desplegar (deploy) nuestras aplicaciones o web sites.
El problema es que si uno esta conectandose a varios servidores muchas veces al día y cada uno de estos tiene un password diferente, la cosa se vuelve complicada. Tengo una aplicación que me ayuda a recordar los passwords pero estoy cansado de copiar y pegar el mismo password 10 veces al día.
La solución a este problema es usar un ssh key. Cuando tienes un ssh key configurado no tienes que entrar el password cada vez que te conectas a un servidor que tiene tu “public key”. Para entender mejor un public key es como una cerradura en una puerta y el private key es la llave que lo abre. Puedes poner la misma cerradura a muchas puertas (servidores) y usar la misma llave para entrar a todas.
Para entender más facilmente (suponiendo que sabes trabajar con ssh):
- Tienes que crear un Public y un Private key
- Debes guardar el private key como si tu vida dependiera de ello
- Debes enviar el public key a todos los servidores o computadoras que te quires conectar
1. En tu computadora personal (Mac OS X / Linux) debes crear el Private y Public key. Esto es muy fácil, simplemente abre el terminal y entra:
ssh-keygen
Luego de entrado este comando te preguntará por un nombre para la pareja de “keys”. En este caso para dejar el nombre que pone por defecto, presionando enter en el teclado. Esto produce tanto el Public (id_rsa) como el Private key (id_rsa.pub). Luego te preguntará por un “passphrase” para el que puedes poner lo que quieras, pero debes recordarlo. Los dos files (id_rsa y id_rsa.pub) se crearán en el directorio .ssh dentro del home folder. Es importante el nombre de estos ficheros, a que renombrándolos no me ha funcionado.
2. Haz un backup de estos dos files. Son muy importantes y si alguien tiene acceso a ellos tambien tendrá acceso a todos los servidores o computadoras que usen esa pareja de llaves.
3. Ahora vamos a colocar el public key (id_rsa.pub) o la cerradura de la puerta al servidor donde queremos conectarnos. Para esto es necesario hacer login al servidor remoto via ssh para decirle que use este file cuando se este tratando de hacer un login desde nuestra computadora personal.
Verifica que el directorio .ssh tiene permisos 700. Si no haces:
chmod 700 .ssh/
cd ~/.ssh
Ahora hay que crear un file para guardar los keys que este servidor acepta.
touch authorized_keys
chmod 600 authorized_keys
Ahora hay que poner nuestro Public key en este file.
Copiamos el contenido de id_rsa.pub con :
cat id_rsa.pub
Editamos el fichero donde almacenaremos esta clave:
joe /root/.ssh/authorized_keys
y pegaremos el contenido del id_rsa.pub que generamos en el servidor o equipo desde el que queremos acceder.
Listo ahora debemos volver a nuestra computadora personal. Si todo salió bien el servidor deberia permitirte conectarte sin perdir ningun password mas allá del passphrase que usaste al principio para genera los keys. De este momento en adelante podrás conectarte al servidor remoto usando solamente:
En caso de tener algún problema al conectarnos por ssh del tipo:
WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
debemos editar el fichero “known_hosts” para eliminar la línea que ha almacenado cuando nos hemos conectado anteriormente desde la misma IP, para ello ejecutamos:
#ssh-keygen -f "/root/.ssh/known_hosts" -R [IP]:PUERTO_SSH
ejemplo:
#ssh-keygen -f "/root/.ssh/known_hosts" -R [192.168.0.1]:22
Aquí les dejo el enlace al mejor articulo que encontré sobre el tema.
Crear un servidor https en IIS
Crear un servidor https en IIS
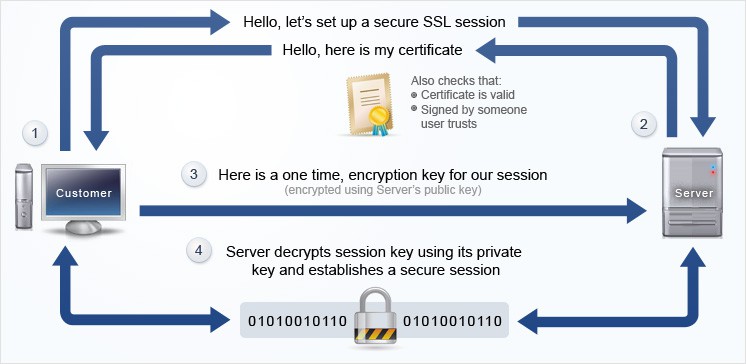
Las firmas digitales sirven para encriptar información, por un lado tenemos la firma pública que junto con una clave privada nos permite firmar digitalmente un documento. Ese documento o información viajará por la red de forma encriptada y únicamente el receptor a partir de su clave privada podrá descifrar el mensaje.
Cuando montamos un servidor https, estamos intentando hacer algo parecido queremos que nuestros datos (dni, tarjetas, claves, etc.) viajen por la red cifrados, es decir entre la capa TCP y la HTTP vamos a insertar la capa SSL.
Un CSR (Certificate Signing Request) es un bloque de texto cifrado que se puede generar en el servidor donde el certificado SSL será utilizado, aunque también existe la posibilidad de generarlo online o a través de aplicaciones.
- https://gethttpsforfree.com/
- https://zerossl.com/free-ssl/#crt
- https://www.sslforfree.com/
- https://certifytheweb.com/home/download
El CSR incluirá entre otras cosas:
- Datos de la empresa de la empresa (organization)
- Dominios para los que han sido generados (common name)
- La clave pública (que será generada automáticamente)
Luego por otro lado necesitas CA (Certificate Authority) o Autoridad Certificadora que es la empresa que debe generar tu SSL a partir del CSR. Hay varias empresas empresas que hacen esta labor, pero casi todas son de pago excepto algunas gratuitas que te proporcionan un certificado con una caducidad rápida de 30 a 90 días.
- Certbot, es una empresa que nos proporciona certificados de forma gratuita para sistemas linux.
- Sino queremos liarnos mucho Certify the Web, nos proporciona una herramienta de pago para la gestión de nuestros certificados en sistemas windows (la versión gratuita tiene un límite de 5 dominios)
Certificado SSL gratis de Let’s Encrypt
Obtener un certificado para nuestro servidor HTTPS
rsync para hacer copias de seguridad
En ¿Piensas en si un día te roban el portátil? mencioné que me gusta hacer los backups con rsync. Me gusta usarlo para backups tanto locales (copiar ficheros de un directorio a otro del mismo sistema) como remotos (copiar ficheros de un sistema a otro), y tanto en en Linux como en Windows usando Cygwin sin ningún problema de interoperabilidad para hacer backups remotos usando uno u otro como destino de las copias de seguridad.
rsync es una herramienta para sincronizar los ficheros y directorios que tenemos almacenados en un sitio en otro diferente minimizando la transferencia de datos (Wikipedia: rsync). En realidad, rsync son dos cosas: un algoritmo de delta compression para sincronizar dos ficheros similares y una utilidad que usa dicho algoritmo junto con otras técnicas para hacer mirroring de ficheros y directorios en otro sitio transfiriendo la mínima cantidad de datos posible.
A nivel de un árbol de directorios con sus ficheros, la idea es sencilla. rsync nos copiará esos ficheros y directorios tal y como estaban en el nuevo sitio pero sin copiar todo, sino sólo lo que ha cambiado en el origen respecto al destino. Hacer lo mismo copiando los ficheros y directorios, incluso en remoto usando una carpeta compartida, sería equivalente si nos fijamos únicamente en el resultado, pero tenemos que transferir mucha más información.
A nivel de ficheros individuales, podemos imaginar un fichero muy grande (p.e. de varios GiB) de una base de datos. Si quisiéramos hacer backup de él sin tener herramientas como rsync, tendríamos que copiarlo cada vez, cuando en realidad en muchos casos la inmensa mayoría de bloques del fichero no habrá cambiado. rsync, en cambio, analiza el fichero en origen y en destino y sólo transmite (de forma comprimida, además) las partes que realmente hayan cambiado.
Debian, por ejemplo, pone a nuestra disposición servidores de rsync para descargar sus imágenes de CDs, aunque hay un debate sobre si el descenso en el uso de ancho de banda de los servidores compensa el aumento en el uso de CPU y memoria a causa del propio algoritmo de rsync (About integration of rsync and Debian). Y es que rsync consume la CPU necesaria para su algoritmo y además mantiene en memoria una lista con todos los ficheros a ser sincronizados (unos 100 bytes por cada uno), por lo que necesita bastante memoria. También se debate el problema de que el rsync no es muy eficiente con ficheros comprimidos con gzip y con bzip2 porque un pequeño cambio en el contenido modifica en cadena todo el archivo creando una especie de efecto mariposa que causa que dos archivos parecidos no guarden ninguna semejanza aprovechable por rsync tras la compresión.
En cualquier caso, si las anteriores pequeñas pegas no nos detienen, veremos que rsync es, en definitiva, una excelente utilidad de línea de comandos para hacer copias de seguridad locales y remotas.
El listado de características especiales que nos da la página de man de rsync es:
- Soporte para copiar enlaces, ficheros de dispositivo, propietarios, grupos y permisos
- Opciones de exclusión (
excludeyexclude-from) similares a las del GNU tar - Modo CVS para ignorar los fichero que CVS ignoraría
- Se puede usar cualquier shell remota transparente, como ssh o rsh
- No es necesario ser
rootpara usarlo - pipelining de los ficheros transferidos para minimizar la latencia
- Soporte para usuarios anónimos o autentificados usando el demonio de
rsync(ideal para hacer mirroring)
En su forma más sencilla de uso, es similar a un cp. Si queremos sincronizar un fichero en otro podemos, simplemente, hacer (el -v es para que nos muestre información más detallada sobre lo que hace):
$ ll fichero1 -rw-r----- 1 vicente users 7625431 2008-01-13 11:40 fichero1 $ rsync -v fichero1 fichero2 fichero1 sent 7626448 bytes received 42 bytes 15252980.00 bytes/sec total size is 7625431 speedup is 1.00 $ ll fichero? -rw-r----- 1 vicente users 7625431 2008-01-13 11:40 fichero1 -rw-r----- 1 vicente users 7625431 2008-01-13 11:41 fichero2
Pero si el comando lo ejecutamos desde otro usuario (en el ejemplo root), vemos que no se está manteniendo el usuario, aunque sí los permisos, y que incluso la hora es diferente:
# rsync fichero1 fichero3 # ll fichero? -rw-r----- 1 vicente users 7625431 2008-01-13 11:40 fichero1 -rw-r----- 1 vicente users 7625431 2008-01-13 11:41 fichero2 -rw-r----- 1 root root 7625431 2008-01-13 11:44 fichero3
Y tampoco es capaz de hacer nada con directorios:
$ rsync dirA dirB skipping directory dirA
Por eso, para propósitos de backup, el rsync en la mayoría de los casos se utiliza con la opción -a:
-a, --archive archive mode; same as -rlptgoD (no -H, -A)
Esta opción combina el parámetro -r para que el recorra toda la estructura de directorios que le indiquemos, el -l para que copie enlaces simbólicos como enlaces simbólicos, la -p para que mantenga los permisos, la -t para que se mantenga la hora del fichero, la -g para que se mantenga el grupo, la -o para que se mantenga el propietario, la -D para que se mantengan los ficheros de dispositivo (sólo para root). Ni se mantienen los hard links (-H) ni las ACLs (-A) por defecto. En definitiva, con la opción -a obtenemos una copia exacta de una jerarquía de ficheros y directorios.
Veamos un ejemplo de sincronización de un directorio llamado dirA que contiene otros directorios y ficheros en otro llamado dirB que, de momento, aún no existe:
$ rsync -av dirA/ dirB/ building file list ... done created directory dirB dirA/ dirA/fichero1 dirA/fichero2 dirA/dirA1/ dirA/dirA1/fichero3 dirA/dirA2/ dirA/dirA2/fichero4 sent 6540542 bytes received 126 bytes 13081336.00 bytes/sec total size is 6539349 speedup is 1.00
Si ahora modificamos un poco sólo uno de los ficheros y volvemos a ejecutar exactamente el mismo comando, veremos que esta vez sólo se copia el fichero modificado:
$ echo prueba >> dirA/fichero1 $ rsync -av dirA dirB building file list ... done fichero1 sent 65884 bytes received 42 bytes 131852.00 bytes/sec total size is 6539356 speedup is 99.19
Sin embargo, vemos que aunque el fichero sea sólo ligeramente distinto, rsync copia todo el fichero completo cada vez:
$ rm fichero2 $ rsync -av fichero1 fichero2 fichero1 sent 7626462 bytes received 42 bytes 15253008.00 bytes/sec total size is 7625445 speedup is 1.00 $ echo prueba >> fichero1 $ rsync -av fichero1 fichero2 fichero1 sent 7626469 bytes received 42 bytes 15253022.00 bytes/sec total size is 7625452 speedup is 1.00
No es que haya ningún defecto en su algoritmo, es que para un uso en local, rsync usa la opción -W por defecto, ya que considera que el esfuerzo en calcular la diferencia entre los ficheros es mayor que copiar directamente todo el fichero:
-W, --whole-file copy files whole (without rsync algorithm)
Si contrarrestamos la -W con --no-whole-file veremos que que ahora sí que sólo copia el bloque donde ha encontrado el cambio:
$ echo prueba >> fichero1 $ rsync -av --no-whole-file fichero1 fichero2 building file list ... done fichero1 sent 13514 bytes received 16620 bytes 20089.33 bytes/sec total size is 7625459 speedup is 253.05
Y si encima usamos la opción -z, comprimirá el bloque antes de pasarlo:
$ echo prueba >> fichero1 $ rsync -avz --no-whole-file fichero1 fichero2 building file list ... done fichero1 sent 843 bytes received 16620 bytes 34926.00 bytes/sec total size is 7625466 speedup is 436.66
El uso de la opción -z puede ser beneficioso o perjudicial, ya que la menor transferencia de datos redunda en un mayor consumo de CPU.
Por cierto, ¿en qué se basa rsync para decidir que un fichero ha cambiado? Normalmente sólo mira la fecha del fichero y su tamaño, por lo que si ninguna de las dos cosas cambia, por defecto el rsync no copiará el fichero. Es muy raro que dos ficheros con la misma fecha y tamaño sean diferentes, pero puede ocurrir. Si en nuestro entorno se puede dar ese caso, tendremos que usar la opción -c para que se determine por CRC si realmente los ficheros son iguales:
-c, --checksum skip based on checksum, not mod-time & size
Pero claro, esto también aumentará sensiblemente el uso de CPU.
La barra al final de los nombres de directorio
Respecto a cómo pasarle los nombres de los directorios, hay que tener una especial atención respecto a si ponemos una barra al final del nombre del directorio o no, ya que significan cosas distintas:
You can think of a trailing / on a source as meaning “copy the contents of this directory” as opposed to “copy the directory by name”, but in both cases the attributes of the containing directory are transferred to the containing directory on the destination. In other words, each of the following commands copies the files in the same way, including their setting of the attributes of
/dest/foo:
rsync -av /src/foo /dest
rsync -av /src/foo/ /dest/foo
Efectivamente, /path/foo significa “el directorio foo“, mientras que /path/foo/ significa “lo que hay dentro de foo“. Pongamos algunos ejemplos para entenderlo.
Este es el uso más estándar en el que sincronizamos dos directorios (dirA y dirB) para que sean exactamente iguales (“rsync -av dirA/ dirB/” o “rsync -av dirA/ dirB“):
$ rm -rf dirB $ rsync -av dirA/ dirB/ building file list ... done created directory dirB ./ fichero1 fichero2 dirA1/ dirA1/fichero3 dirA2/ dirA2/fichero4 sent 6540550 bytes received 126 bytes 13081352.00 bytes/sec total size is 6539363 speedup is 1.00 $ ll dirB total 164 drwxr-xr-x 4 vicente users 4096 2008-01-13 11:48 ./ drwxr-xr-x 4 vicente users 4096 2008-01-13 14:00 ../ drwxr-xr-x 2 vicente users 4096 2008-01-13 11:48 dirA1/ drwxr-xr-x 2 vicente users 4096 2008-01-13 11:59 dirA2/ -rwxr-xr-x 1 vicente users 65638 2008-01-13 13:59 fichero1* -rw-r--r-- 1 vicente users 71033 2008-01-13 11:39 fichero2
En cambio, si lo que queremos es que que copie dirA dentro de dirB, tenemos que poner “rsync -av dirA dirB/” o “rsync -av dirA dirB“:
$ rm -rf dirB $ rsync -av dirA dirB building file list ... done created directory dirB dirA/ dirA/fichero1 dirA/fichero2 dirA/dirA1/ dirA/dirA1/fichero3 dirA/dirA2/ dirA/dirA2/fichero4 sent 6540549 bytes received 126 bytes 13081350.00 bytes/sec total size is 6539356 speedup is 1.00 $ ll dirB total 12 drwxr-xr-x 3 vicente users 4096 2008-01-13 13:35 ./ drwxr-xr-x 4 vicente users 4096 2008-01-13 13:35 ../ drwxr-xr-x 4 vicente users 4096 2008-01-13 11:48 dirA/
La diferencia entre poner la barra al final y no ponerla es una de las cosas que tenemos que tener en todo momento más claras a la hora de pensar en qué parámetros le vamos a pasar al comando para hacer un backup con rsync con éxito.
Eliminando ficheros del destino de backups anteriores
En muchos casos, es posible que hayamos borrados ficheros de origen que ya no queremos que aparezcan en el destino, pero por defecto rsync no los elimina. Para que lo haga, debemos usar la opción --delete:
$ rm -rf dirB/ $ rsync -a dirA/ dirB/ $ touch dirB/ficheroextraño $ rsync -av dirA/ dirB/ building file list ... done ./ sent 199 bytes received 26 bytes 450.00 bytes/sec total size is 6539363 speedup is 29063.84 $ rsync -av --delete dirA/ dirB/ building file list ... done deleting ficheroextraño ./ sent 199 bytes received 26 bytes 450.00 bytes/sec total size is 6539363 speedup is 29063.84
Cuando se hagan pruebas con el --delete hay que llevar mucho cuidado, porque si elegimos erróneamente el directorio de destino podemos borrar en cascada muchísimos ficheros que no queríamos borrar. Es por eso que se aconseja que se use en las pruebas la opción -n/--dry-run para que el comando no haga nada en realidad y así podamos depurar el comando antes de ponerlo en funcionamiento definitivamente.
Otra opción que puede ser interesante en algunos entorno es la -u, para que no se sobreescriban los ficheros del destino que son más recientes que los del origen. Esta opción es útil si es posible que en un momento dado se trabaje sobre los ficheros del backup, de modo que en ningún caso reemplacemos los archivos que se puedan haber modificado en destino:
$ touch dirB/fichero1 $ rsync -av --delete dirA/ dirB/ building file list ... done fichero1 sent 65885 bytes received 42 bytes 131854.00 bytes/sec total size is 6539363 speedup is 99.19 $ touch dirB/fichero1 $ rsync -av --delete -u dirA/ dirB/ building file list ... done sent 193 bytes received 20 bytes 426.00 bytes/sec total size is 6539363 speedup is 30701.23
Y en este punto, ya tenemos varias forma de usar el comando perfectamente válidas para hacer backups en función de nuestras necesidades:
$ rsync -av --delete directorioorigen/ directoriodestino/ $ rsync -av --delete directorioorigen directoriodestino $ rsync -av --delete -u directorioorigen/ directoriodestino/ $ rsync -av --delete -u directorioorigen directoriodestino
Backups incrementales
Si queremos tener un archivo con los ficheros que vamos modificando, un backup incremental, las opciones -b/--backup y --backup-dir=DIR (y también --suffix=SUF) son de mucha utilidad para nosotros.
Supongamos que tenemos dos directorios dirA y dirB perfectamente sincronizados y actualizamos un fichero en el directorio origen:
$ rsync -a dirA/ dirB/ $ echo prueba >> dirA/fichero1
Si volvemos a sincronizar, el rsync borraría el dichero dirA/fichero1 que teníamos almacenado del backup anterior en dirB. Para que no nos lo elimine completamente, vamos a usar la opción -b y le vamos a decir que almacene la versión previa en el directorio “backup_fechahoradehoy” (ponemos dos opciones -v para que nos informe sobre el backup):
$ rsync -avvb --delete --backup-dir=$PWD/rsync/backup_$(date +%y%m%d%H%M) dirA/ dirB/ backup_dir is /home/vicente/rsync/backup_0801131917/ building file list ... done deleting in . delta-transmission disabled for local transfer or --whole-file fichero1 fichero2 is uptodate dirA1/fichero3 is uptodate dirA2/fichero4 is uptodate backed up fichero1 to /home/vicente/rsync/backup_0801131917/fichero1 total: matches=0 hash_hits=0 false_alarms=0 data=65708 sent 65991 bytes received 78 bytes 132138.00 bytes/sec total size is 6539433 speedup is 98.98
Y vemos que ya tenemos un directorio de backup que sólo contiene los fichero que han sido reemplazados esta vez:
$ ll total 20 drwxr-xr-x 5 vicente users 4096 2008-01-13 19:18 ./ drwxr-x--- 56 vicente users 4096 2008-01-13 18:43 ../ drwxr-xr-x 2 vicente users 4096 2008-01-13 19:17 backup_0801131917/ drwxr-xr-x 4 vicente users 4096 2008-01-13 11:48 dirA/ drwxr-xr-x 5 vicente users 4096 2008-01-13 11:48 dirB/ $ ll backup_0801131917/ total 80 drwxr-xr-x 2 vicente users 4096 2008-01-13 19:17 ./ drwxr-xr-x 5 vicente users 4096 2008-01-13 19:18 ../ -rwxr-xr-x 1 vicente users 65701 2008-01-13 19:17 fichero1*
Si ahora modificamos otro fichero, veremos que antes de reemplazarse, se almacenará en un nuevo directorio de backup:
$ echo prueba >> dirA/fichero2 $ rsync -ab --delete --backup-dir=$PWD/backup_$(date +%y%m%d%H%M) dirA/ dirB/ $ ll total 28 drwxr-xr-x 7 vicente users 4096 2008-01-13 19:21 ./ drwxr-x--- 56 vicente users 4096 2008-01-13 18:43 ../ drwxr-xr-x 2 vicente users 4096 2008-01-13 19:17 backup_0801131917/ drwxr-xr-x 2 vicente users 4096 2008-01-13 19:21 backup_0801131921/ drwxr-xr-x 4 vicente users 4096 2008-01-13 11:48 dirA/ drwxr-xr-x 4 vicente users 4096 2008-01-13 11:48 dirB/ $ ll backup_0801131921/ total 84 drwxr-xr-x 2 vicente users 4096 2008-01-13 19:21 ./ drwxr-xr-x 7 vicente users 4096 2008-01-13 19:21 ../ -rw-r--r-- 1 vicente users 71040 2008-01-13 19:20 fichero2/
Es importante no usar paths relativos en el parámetro --backup-dir, porque son relativos al directorio destino. En los ejemplos anteriores, si hubiéramos hecho “--backup-dir=backup_$(date +%y%m%d%H%M)“, el directorio “backup_0801131917” de turno se hubiera creado dentro del dirB y sería eliminado en el siguiente rsync con --delete.
Actualización 15/1/07 (inspirada por los comentarios de MetalAgent):
También podemos hacer backups incrementales con las opciones:
--compare-dest=DIR also compare received files relative to DIR --copy-dest=DIR ... and include copies of unchanged files --link-dest=DIR hardlink to files in DIR when unchanged
La opción --compare-dest=DIR hace casi lo mismo que la -b/--backup / --backup-dir=DIR, pero al revés. En lugar de guardar los ficheros viejos en DIR, como hace la -b, la --compare-dest lo que hace es guardar en el directorio destino sólo los ficheros que han cambiado respecto a DIR. Es como un backup incremental pero mientras que con la -b tienes todos los ficheros de la última versión en el directorio destino, con la --compare-dest sólo tienes en el directorio destino los ficheros que han cambiado desde el último backup.
Como variación de la --compare-dest, está la --copy-dest=DIR, que hace lo mismo que la anterior pero además copia los ficheros que no hayan cambiado. ¡Pero ojo!, la ventaja de esta opción es que la copia de los ficheros que no han cambiado es local, de forma que en un rsync remoto, todos los ficheros que ya estaban en DIR no se tienen que transferir. La desventaja es que necesita mucho espacio en disco.
Finalmente, la variante más interesante es la --link-dest=DIR, que hace lo mismo que la --copy-dest pero sin consumir más espacio en disco porque usa hard links a los ficheros que ya existen. ¡Una opción realmente útil!
Incluyendo y excluyendo ficheros del backup
La mayoría de las veces no querremos hacer backup de un único directorio y ya está, sino que querremos hacer backup de una lista determinada de directorios. En esos casos, o especificamos uno por uno en la línea de comandos o, mucho mejor, los especificamos en una lista. Si especificamos los ficheros en una lista, nos podemos permitir tener un script de backup que lance rsync con las opciones deseadas y que no modificaremos nunca y el fichero con la lista de directorios de los que hay que hacer backup que será lo que modificaremos. Las opciones son:
--exclude=PATTERN exclude files matching PATTERN --exclude-from=FILE read exclude patterns from FILE --include=PATTERN don't exclude files matching PATTERN --include-from=FILE read include patterns from FILE --files-from=FILE read list of source-file names from FILE
Los patrones que usa rsync no son muy intuitivos, así que lo mejor es leer detenidamente la sección que los explica (INCLUDE/EXCLUDE PATTERN RULES) en la página de man de rsync, pero podemos ver un ejemplo que nos aclarará un poco este tema.
Imaginemos que queremos hacer un backup de los directorios “/var/log/” y “/var/www/“. Podríamos usar un comando como:
rsync -av --delete --prune-empty-dirs --include-from=lista_dirs_backup.txt / /mnt/disco/Backup/
en el que el fichero lista_dirs_backup.txt contiene:
+ */ + /var/www/** + /var/log/** - *
El “+ */” de la primera línea especifica que todos los directorios pasan el filtro y es necesario porque aunque especifiquemos los directorios que nos interesan en las siguientes líneas, el propio directorio /var/ y los /var/log/ y /var/www/ no pasaría el filtro. Además, como esta opción nos permite pasar todos los directorios pero sin los ficheros y directorios que contienen, tenemos que usar la opción --prune-empty-dirs para que no copie directorios vacíos.
En la última línea le especificamos con “- *” que todo lo que en ese punto ya no ha pasado el filtro, que sea descartado. Los dos asteriscos (**) indican que todos los ficheros y directorios que hay debajo pasarán el filtro.
Una alternativa sin --prune-empty-dirs sería incluir específicamente todos los directorios involucrados:
+ /var/ + /var/www/ + /var/log/ + /var/www/** + /var/log/** - *
Pero es evidente que en el caso de tener muchos directorios y con mucha profundidad, esta forma se puede complicar mucho y es claramente más sencilla la anterior (aunque también es más lenta por tener que recorrer todos los directorios del origen).
En versiones de rsync >=2.6.7 también existe la posibilidad de poner tres asteriscos (***) para especificar que el propio directorio especificado también pasa el filtro, facilitándonos nuestra labor en el caso de que queramos hacerlo sin “+ */” y sin --prune-empty-dirs:
+ /var/ + /var/www/*** + /var/log/*** - *
Y también es importante tener en cuenta si los directorios especificados son relativos o absolutos. En los ejemplos anteriores, el directorio origen era el raíz (/) y por ello, los directorios se guardaban con todo el path (/var/log/ y /var/www/) y así los especificábamos en el fichero de include:
$ ll /mnt/disco/Backup/var/ total 16 drwxr-xr-x 4 root root 4096 2007-10-31 21:10 ./ drwxr-xr-x 3 root root 4096 2007-12-09 18:19 ../ drwxr-xr-x 14 root root 4096 2008-01-13 18:43 log/ drwxr-xr-x 3 root root 4096 2007-06-27 20:19 www/
pero también podríamos haber decidido hacerlo con referencia a /var/:
rsync -av --delete --prune-empty-dirs --include-from=lista_dirs_backup.txt /var/ /mnt/disco/Backup/
Con lo que en el fichero lista_dirs_backup.txt tendríamos que poner (suponemos versión <2.6.7):
+ www + log + www/** + log/** - *
Y el resultado sería un backup sin la parte del directorio /var/:
$ ll /mnt/disco/Backup/ total 16 drwxr-xr-x 4 root root 4096 2007-10-31 21:10 ./ drwxrwxrwt 18 root root 4096 2008-01-13 20:07 ../ drwxr-xr-x 14 root root 4096 2008-01-13 18:43 log/ drwxr-xr-x 3 root root 4096 2007-06-27 20:19 www/
Pero como regla fácil que siempre funciona, tenemos lo primero que hemos comentado. Un comando como este:
rsync -av --delete --prune-empty-dirs --include-from=lista_dirs_backup.txt / /mnt/disco/Backup/
con un lista_dirs_backup.txt como este:
+ */ + /directorio1/** + /directorio2/directorio2A/** + /directorio2/directorio2B/** - *
rsync remoto
Hasta ahora hemos hecho todos los ejemplos en local. Sin embargo, la máxima utilidad de rsync llega cuando se usa para hacer backups en una máquina remota, de forma que el backup cumpla mejor su función al estar físicamente en otro sistema.
En la máquina destino es posible usar el propio proceso rsync funcionando como demonio y escuchando por defecto en el puerto 873 para recibir estas conexiones, pero es mucho más cómodo y fácil hacerlo por SSH, algo para lo que rsync ya está preparado por defecto.
Para esto es conveniente configurar el cliente y el servidor de SSH involucrados para entrar de forma transparente usando autentificación por clave pública (Autentificación trasparente por clave pública/privada con OpenSSH) para evitar tener que introducir la contraseña cada vez, aunque no es estrictamente necesario. Una vez que lo tengamos así (o si optamos por introducir la contraseña manualmente) y verifiquemos que podemos entrar en la otra máquina sin introducir usuario ni contraseña, podemos usar rsync exactamente igual que si trabajáramos con la máquina local, solo que tenemos que especificar el prefijo “usuario@maquina:” en el origen o en el destino (no en ambos):
$ rsync -av --delete dirA vicente@remoto:/backup/ building file list ... done dirA/ dirA/fichero1 dirA/fichero2 dirA/dirA1/ dirA/dirA1/fichero3 dirA/dirA2/ dirA/dirA2/fichero4 sent 6540658 bytes received 126 bytes 2616313.60 bytes/sec total size is 6539461 speedup is 1.00
# rsync -av --delete vicente@remoto:/backup/dirA/ dirC/ receiving file list ... done created directory dirC ./ fichero1 fichero2 dirA1/ dirA1/fichero3 dirA2/ dirA2/fichero4 sent 126 bytes received 6540665 bytes 2616316.40 bytes/sec total size is 6539461 speedup is 1.00
rsync + sshpass: copias de seguridad remotas
Veamos como crear un script para realizar una copia de seguridad remota entre dos servidores.
Supongamos que tenemos dos servidores remotos uno que llamaremos «producción» y otro que llamaremos «backup», ambos están corriendo el mismo sistema operativo Linux, una versión CentOS 7 . La idea es crear un script sobre el servidor «producción» que se ejecutará mediante un «crontab» todas las noches, ese escript realizará una copia de los archivos de una determinada carpeta y además necesitamos realizar la copia de la base de datos de un determinado usuario de MySQL. Por otro lado tenemos una unidad NAS en la red local del servidor donde realizaremos una copia semanal del servidor de backup. Veamos el siguiente esquema para terminar de entender el problema que planteamos:
Para poder desarrollar esta solución tenemos que tener instalados estos tres programas:
- rsync: que será el programa principal que realizará las copias
- sshpass: necesario para poder hacer la validación automática del usuario, ya que la idea del script es que se ejecute de forma auomática por la noche, para ser lanzado desde un crontab, y teniendo en cuenta que rsync no para poder hacer la copia remota siempre nos pedirá el usuario y la contraseña del servidor remoto, es por lo que necesitamos de la ayuda de sshpass para poder hacer la validación.
- ftp: el cliente de ftp realizará la copia de seguridad del servidor Backup a la unidad NAS.
yum install ftp sshpass rsync
Creando ficheros de respaldo
Lo primero que haremos es un script para crear un fichero que incluya un «mysqldump» para cada una de las bases de datos que queramos respaldar:
#!/bin/bash mysqldump --user=usuario1 --password=pwdusuario1 nombre-bbdd > /ruta-de-la/copia/bbddusuario1.sql mysqldump --user=usuario2 --password=pwdusuario2 nombre-bbdd > /ruta-de-la/copia/bbddusuario2.sql ... mysqldump --user=usuariox --password=pwdusuariox nombre-bbdd > /ruta-de-la/copia/bbddusuariox.sql
Si quisieramos copiar todas las bases de datos con una única instrucción:
#!/bin/bash mysqldump --user=root --password=pwddelroot --all-databases > /ruta-de-la/copia/todotodotodo.sql
Por último si queremos tener un fichero por cada una de las bases de datos y para cada día, también podemos realizarlo de esta manera más elegante.
#! /bin/bash TIMESTAMP=$(date +"%F") BACKUP_DIR="/ruta-de-la/copia/$TIMESTAMP" MYSQL_USER="root" MYSQL=/usr/bin/mysql MYSQL_PASSWORD="passwordroot" MYSQLDUMP=/usr/bin/mysqldump mkdir -p "$BACKUP_DIR/mysql" databases=`$MYSQL --user=$MYSQL_USER -p$MYSQL_PASSWORD -e "SHOW DATABASES;" | grep -Ev "(Database|information_schema|performance_schema)"` for db in $databases; do $MYSQLDUMP --force --opt --user=$MYSQL_USER -p$MYSQL_PASSWORD --databases $db | gzip > "$BACKUP_DIR/mysql/$db.gz" done
Comprimir archivos
Luego para ahorrar espacio y hacer que la transmisión sea más rápida ahorrando ancho de banda, comprimiremos dichos archivos.
#!/bin/bash tar cvzf /ruta-de-la/copia/CopiaTotal.tgz /ruta-de-la/copia/
Si queremos más compresión a cambio de más procesador para comprimir y descomprimir podemos utilizar el algoritmo bz2 (tar.bz2=tbz=tb2):
#!/bin/bash tar cvfj /ruta-de-la/copia/CopiaTotal.tar.bz2 /ruta-de-la/copia/
Ahora enviamos los archivos:
rsync -avzh --rsh="/usr/bin/sshpass -p claveusuarioremoto ssh -l usuarioremoto" /ruta-de-la/copia/* ip-maquina-remota:/ruta-del/backup
Restaurar base de datos
mysql --user=nombreusuerbbdd --password=pwduserbbdd nombre_bbdd < /ruta-de-la/copia/archivo_dump.SQL